
Unsupervised Pre-training of Image Features on Non-Curated Data
Code && Paper
名词解释
- curated-data:整理过后的数据,一般不会存在类别不平衡现象,例如ImageNet,没有长尾分布。
- 如果按照监督信息的强弱排名的话:标记数据>无标记数据(curated data)>无标签数据(non-curated data)
问题定义
Related Work
- Self-supervised learning:利用另一个模型或者某些规则生成一个伪label(pseudo label),基于这些pseudo label去优化我们的target network。代表的就是伪label
- Clustering:利用聚类算法的思想,生成label或者对应的feature representation。代表的是cluster的assignment。
- 对于self-supervised learning的方法来说,他对于数据的分布是相对稳定的,但是他不能捕捉图像之间的统计信息。但是对于Deep Clustering的方法来说,他对于数据的分布是不稳定的,不同的数据分布会导致不同的聚类效果。但是他可以考虑图像之间的统计信息。如下图所示
| Method | inter-image statistics | stable to distribution change |
|---|---|---|
| Self-Sup | N | Y |
| Deep Clustering | Y | N |
DeeperClustering
idea
上述我们分别介绍了Self-supervised 和 Clustering方法的优缺点,那么我们能不能考虑将两个方法结合起来呢。 一种最直观的解决方案就是将两者的loss相加,但是作者认为如果相加的话,默认两个任务是相对独立的。 为了让其有更多的相互影响,作者采用了笛卡尔乘积来将两者结合: 也就是将两者concat。
但是上述的笛卡尔乘积方式当某一个维度很长的时候,会造成latent space很大,所以为了解决该问题,作者提出了分层的DeeperClustering方法。
overview
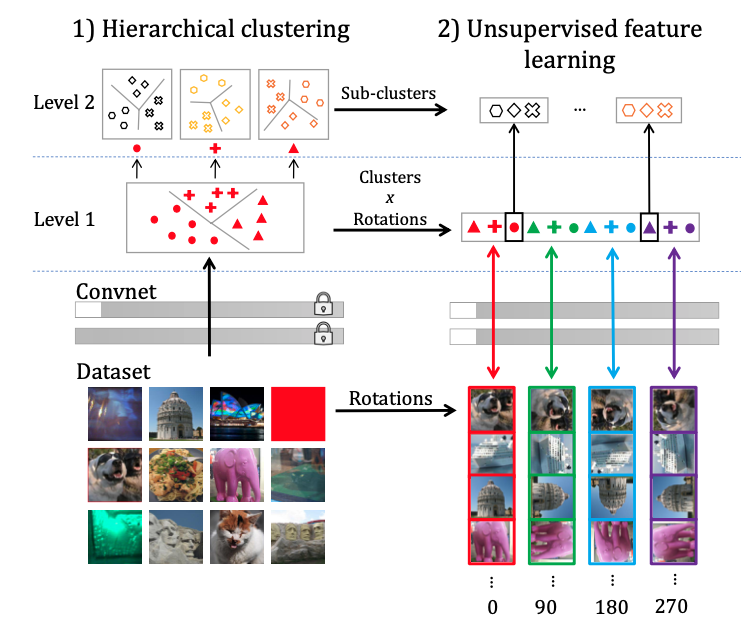
网络结构如下所示,整个训练过程迭代的通过two-step来完成。
- 第一步:通过cluster生成pseudo label。这个过程是分级的,采用两级结构。首先我们通过kmeans对conv输出的特征进行聚类,聚成m类。 然后我们利用self-sup的思想,对每个图像进行旋转0,90,180,270度,所以第一层在训练过程中有4m个class。 我们再对每一个cluster内部再次进行聚类,聚类成K类。所以一共的类别是m*k类。
- 第二步:我们再通过生成的pseudo label进行学习与训练。
Loss function
loss函数定义如下所示。总体上来说有两部分组成。
- 代表的是第一级别的loss函数。一共是4m类,不仅仅有原来的m类,还有旋转后的,所以一共是4m类。
- 代表的是第二级的loss。针对上述的4m类,每一类都有一个分类器,我们计算他的输出和二级聚类的label的loss。