
Invariant Information Clustering for Unsupervised Image Classification and Segmentation
Code && Paper
问题定义
主要思想
- 利用paired的数据,通过最大化他们之间的互信息来优化整个分类器网络。
- 最大化互信息所代表的物理意义最大化已知一个数据的分布情况下,另一个数据分布减少的不确定性。也就是两个数据的相关性强。
- 如何生成paired的数据呢?通过augmentation的方式可以生成paired的数据。
相关工作
作者介绍了在用无监督方式做聚类操作时候的相关工作。主要分为两类。
- 直接端到端的产生label的assignment。代表:DeepCluster
- 分为two-step,首先得到vector representation。然后再通过kmeans这种聚类算法得到label assignment。代表:UTS
DeepCluster: Deep Clustering for Unsupervised Learning of Visual Features
- 主要贡献是在学习vector representation的过程中结合的kmeans算法,流程图如下所示
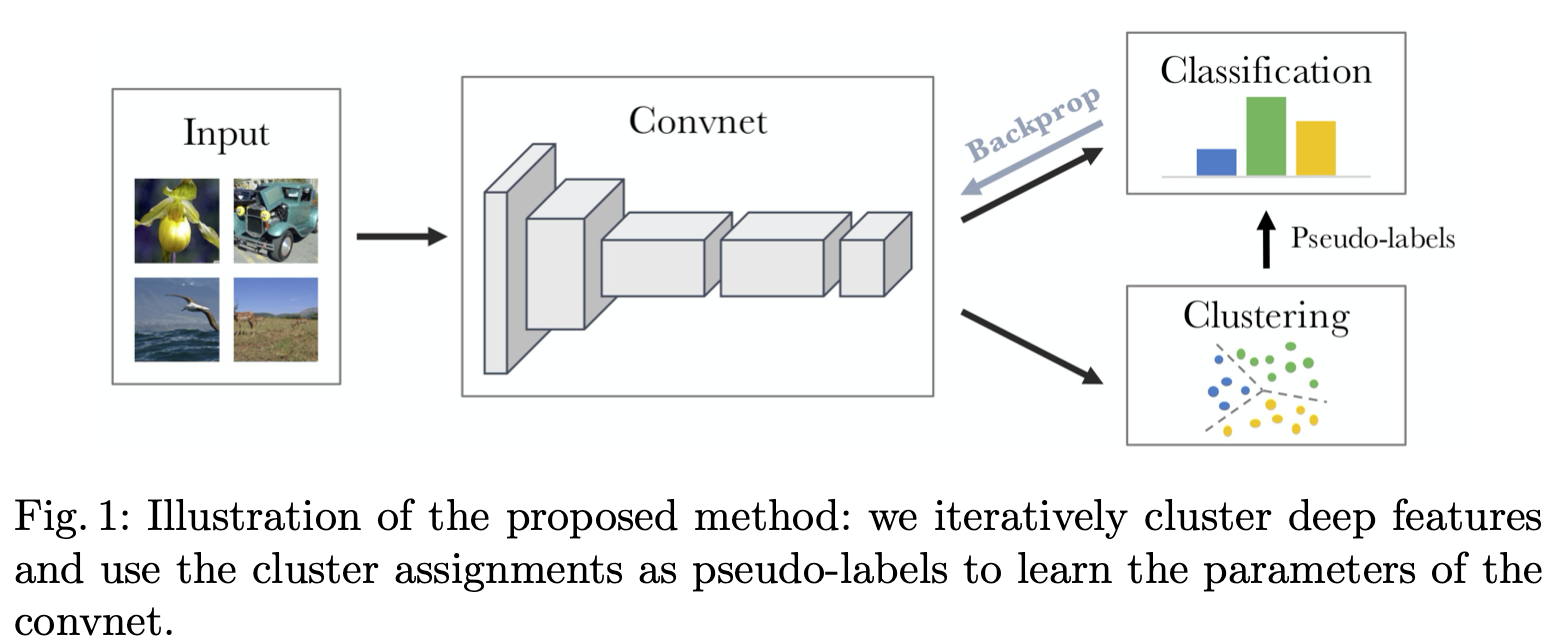
- 主要贡献是在学习vector representation的过程中结合的kmeans算法,流程图如下所示
- 优化的目标如下所示,可以看到如果按照如下目标优化的话,很有可能会出现极端情况的退化:所有的vector都是0,cluster也是0。
- 所以为了避免这种情况出现,作者提出了一种reassign的结果的方案:也就是说当发现每一个cluster A为空的时候,我们就将非空cluster B的中心点加上一些随机噪声,将其作为A的中心点,然后重新assignment。
- 还有一个问题就是类别不平衡的问题。作者将其做了加权重的处理方式。
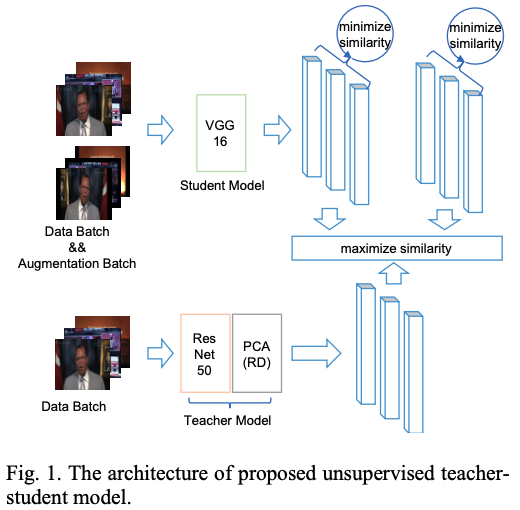
UTS: Unsupervised Teacher-Student Model for Large-Scale Video Retrieval
- 本文主要是利用一种无监督的方式来提取特征,网络流程如下所示。
IIC
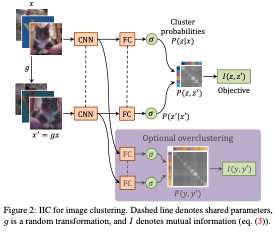
overview
网络结构如下所示,optional clustering代表的是可选的clustering。比如说,我们原有的只需要聚类10类,我们通过optional clustering可以选择聚100类。避免noise data的影响。
Loss function
-
我们知道互信息的定义为,所以我们需要分别计算关于X和Y的边缘概率分布和联合概率分布。 为了计算这两个分布,我们在batch范围内计算一个矩阵P,,其中代表的是分类器的输出,即就是每个class的概率。 在此基础上,我们可以计算I(z,z’),
-
物理意义:互信息可以写成熵减去条件熵的形式:。最大化互信息,就代表着最大化熵,同时也代表着最小化条件熵。前者让每个cluster的概率尽可能相等,后者想要突出某个cluster的概率。所以有点对抗训练的意思。